TidBITS#1165/18-Mar-2013
The big news this week came from Google, not with something new, but with the cancellation of something old: Google Reader. Josh Centers offers some suggestions for alternatives, if you’re accustomed to reading RSS news feeds via Google Reader or syncing them between devices with other RSS apps. And Adam Engst takes advantage of the opportunity to look more deeply into what the shuttering of Google Reader means in terms of tools versus platforms, publishers versus distributors, and the infinitude of Internet information. Bringing things back down to earth, Adam also looks at the OS X 10.8.3 update, and Joe Kissell introduces FlippedBITS, a new column aimed at correcting technology misconceptions, with the first installment aimed at explaining what to watch out for when booting from a duplicate of your hard disk. Notable software releases this week include Security Update 2013-001 for Snow Leopard and Lion, MacBook Pro Retina SMC Update 1.1, Pear Note 3.1, LaunchBar 5.4.2, Microsoft Office 2011 14.3.2 and 2008 12.3.6, Default Folder X 4.5.8, and Dropbox 2.0.
OS X 10.8.3 Mountain Lion Fixes Nagging Bugs
With OS X Mountain Lion 10.8.3 Update and the included Safari 6.0.3, Apple has squashed numerous nagging bugs, many of which were extremely specific and were thus overlooked in the larger 10.8.2 release from nearly six months ago (see “OS X 10.8.2 Eases Notification Center, Messages Frustrations,” 19 September 2012). The free update is available via the Mac App Store, with delta (540.46 MB — from 10.8.2) and combo (793.69 MB — from any version of 10.8) updaters now ready for download from the Apple Support Downloads site. Although we
haven’t noticed any problems yet, we recommend holding off on the update for at least a few days until we’ve seen if it introduces any new issues. Let’s take a look at the details.
Ding dong, the file URL bug is dead! See “A Simple Text String that Crashes Most Mac Applications” (4 February 2013). This bug was minor, but embarrassing, so it’s nice that Apple has addressed it.
The Contacts app fixes several printing-related bugs, including one that caused cards to print out of order and another that caused addresses to print in the wrong location. We still mostly print with BeLight Software’s more-capable Labels & Addresses, so we’ve not run into these problems (see “Labels & Addresses Restores Holiday Card Sanity,” 12 December 2008).
If you use Boot Camp in favor of VMware Fusion or Parallels Desktop, and you want to stay up to date with the latest developments on both sides of the fence, 10.8.3 adds support both for installing Windows 8 and for Macs with 3 TB drives.
Eye candy lovers will be pleased to learn that 10.8.3 finally brings back to Mountain Lion’s Slideshow screensaver the capability to display photos from subfolders, and also fixes a bug that could cause the desktop picture to change after logging out or restarting. If you’ve noticed wackiness on the screen after waking from sleep, that should be a thing of the past too.
Listen up for two audio-related fixes, one that prevents an audio stuttering problem on 2011 Macs, and another that could cause Logic Pro to become unresponsive when using certain plug-ins.
On the networking side, 10.8.3 promises reliability enhancements when using a Microsoft Exchange account in Mail, claims improved compatibility with IMAP servers in the Notes app, prevents Messages from displaying messages out of order after waking from sleep, and includes fixes for two Active Directory bugs that could cause delays on high latency networks and lock out users after accessing the Security & Privacy pane of System Preferences.
Safari 6.0.3 improves performance when scrolling on Facebook and while zoomed in on a Web page, plus while viewing Web pages with plug-in content. Also included are bug fixes for an erroneous alert claiming that bookmarks can’t be changed, duplicate bookmarks on iOS devices after editing them in Safari on the Mac, incorrect access to unfiltered search results when searching Google with Parental Controls enabled, and a problem that prevents Safari from restoring the correct page position when you navigate back to a previous page.
As always, both 10.8.3 and Safari 6.0.3 address numerous security vulnerabilities. Safari 6.0.3 fixes no less than 15 WebKit memory corruption bugs, plus a pair of cross-site scripting attacks. 10.8.3’s security fixes span the gamut, addressing components and apps such as Apache, CoreTypes, International Components for Unicode, Identity Services, ImageIO, IOAcceleratorFamily, the kernel, Login Window, Messages, PDFKit, and QuickTime. Plus, the update no longer allows incorrect SSL certificates.
There’s also mention of a malware removal tool that Apple says will run on installation and will remove most common variants of malware — you’re alerted only if malware is found.
As noted at the start, although the changes in both 10.8.3 and Safari 6.0.3 are welcome, there’s no telling if Apple has inadvertently introduced new problems, so unless you’re being vexed daily by something that these updates fix, we recommend holding off on this update until early adopters give the all clear.
Introducing Our New FlippedBITS Column
Today I’d like to introduce a new series of articles we’re calling FlippedBITS. Our premise is that technology breeds misconceptions, and far too often, due to a lack of information, we develop mental models of the way things work that are plausible — but wrong. Those mistaken ideas, in turn, make it more difficult to solve everyday problems and can lead us to waste time, effort, and money. In each installment of FlippedBITS, I’ll examine one or more of these misconceptions and do my best to set the record straight.
My 2-year-old son is still learning the basics of how the world works, and it’s fascinating to watch his understanding of technology evolve. Just a few months ago, he’d pick up a remote control and try to talk on it like a telephone. In his mind, any oblong plastic box with buttons on one side must be a telephone — it’s easy to see how he might make that mistake. (And, in all fairness, we had a telephone and a remote control that looked mighty similar to each other.) Now he understands that a remote control is different — it’s the thing we point at the TV to make it play his favorite shows. But then he became confused and frustrated when we handed him a toy remote control that only made noise when he pressed the buttons; he
couldn’t understand why the TV wouldn’t respond.
We expect kids to make these kinds of errors, and we laugh knowingly as we watch how they try to put something into one logical category, notice that it doesn’t quite fit, and then try another. This is all part of growing up. But in fact, we never stop trying to make sense of the world. We encounter a new thing we don’t entirely understand, and we automatically — perhaps unconsciously — start trying to construct a mental model of what must be happening behind the scenes. These models not only help us explain what we’re seeing, they help us predict how things will work in the future. It’s just that sometimes, through no fault of our own, we guess wrong.
For example, I remember the first time I heard of this newfangled device called a “laser printer.” I was a freshman in college. I got that paper went in blank and that, due to something involving a laser, it came out with crisp black text. But the initial idea I had about how this worked was that the laser was somehow burning the letters directly on the paper, because after all, burning is what lasers do. Later, when I found out that laser printers used a black powder called toner, I had to revise my theory. Maybe the paper was covered with toner before the laser zapped it, and the heat from the laser caused the toner to melt in spots and stick to the paper. That turned out to be wildly wrong too, of course. I had no idea at the
time that a laser beam could reverse an electrostatic charge that otherwise causes toner to stick to a drum, that when paper rolled along that drum, it picked up the remaining toner (again, due to electrostatic attraction), and that a combination of heat and pressure then fused the toner to the paper. My theories had seemed reasonable based on the available information; they even correctly predicted that the paper would come out of the printer warm. But my mental model didn’t happen to reflect reality.
Misconstruing how a laser printer worked had no negative consequences for me. But sometimes erroneous mental models lead to serious problems. If your mental model of how a car’s air bags work is that they offer complete protection in any sort of crash, that could lead you not to bother wearing a seatbelt, which might prove deadly if, for example, your car flipped over.
I get lots of technical questions from people who have read my books and articles or heard me speak somewhere. A fair percentage of the time, the questions are phrased in a way that shows they come from a mistaken mental model. For example, in the last several weeks at least three different people have asked approximately the same question: “Since FileVault encrypts all the files on my disk, doesn’t that mean when I copy a file to another disk, it’s still encrypted?” No! It absolutely does not mean that. (I’ll explain why in a future FlippedBITS article.) But I can easily see how someone might draw such a conclusion — and misunderstanding something like that could cause someone to make an unsafe decision about how to handle
sensitive files.
I’ll admit it: When I hear questions like this, I sometimes have to fight the temptation to roll my eyes and say, “What an idiotic idea!” But I’ve had (and probably still have) plenty of idiotic misconceptions myself. Not understanding something, or having a faulty conception of how it works, doesn’t make you stupid. It only means you haven’t yet acquired enough information about something. I’ll do my best to supply those missing facts and put us all on the right path. I already have a healthy list of prospective FlippedBITS topics, but if there’s a topic you think might be an appropriate fit, please feel free to suggest it.
So, whence the name “FlippedBITS”? Apart from the fact that we at TidBITS like to append “BITS” to everything, we thought that flipped bits would be an apt description of the kind of error we’re trying to correct. Computers, as you know, store information as a series of ones and zeroes. Every “slot” that can hold either a one or a zero is a bit. If the bit’s value is zero and you flip it, it becomes a one. Flip it again, it’s back to zero. Sometimes bits get flipped inadvertently due to programming errors, mechanical failures, media degradation, cosmic rays — really! — or other random occurrences. And unfortunately, a single flipped bit — a one where a zero should be, or vice-versa — can mean the difference
between a program succeeding and failing. After all, 01110111 is “w” in binary, but 01110011 — almost the same, but with one bit flipped — is “s.” Sometimes a change as small as a single flipped bit can spell the difference between a “win” and a “sin”!
With that, allow me to direct you to the first article in what I hope will be a long and helpful series: “FlippedBITS: Booting Your Mac from a Duplicate” (13 March 2013)
FlippedBITS: Booting Your Mac from a Duplicate
In this first installment of FlippedBITS, I want to look at what happens when you boot your Mac from a duplicate (or “clone”) of your startup disk. In doing so, I hope to clear up several common points of confusion, particularly regarding ongoing backups and syncing other types of data.
For years I’ve recommended a three-pronged backup strategy consisting of versioned backups (such as those produced by Time Machine or CrashPlan), bootable duplicates (complete copies of everything on your startup disk, stored on an external drive), and offsite data storage (either in the cloud or by rotating physical media to other locations). Together, this combination can protect your data against almost any disaster, while making recovery as painless as possible. (For complete details about my suggested strategy, including the steps to create a bootable duplicate, see “Take Control of Backing Up Your Mac.”)
It’s simple enough to make a duplicate using a tool such as Carbon Copy Cloner or SuperDuper; having done that, you can use the duplicate to boot your Mac either by selecting it in the Startup Disk pane of System Preferences or by holding down Option while restarting and selecting the volume containing the duplicate. Doing so enables you to get back to work immediately if anything goes wrong with your startup disk; running from the duplicate makes your Mac behave as though nothing had happened. So far, so good.
But, based on numerous email exchanges I’ve had with people who have read my various books and articles about backups, what happens once you’ve booted from the duplicate is sometimes unclear. Some people expect a duplicate to behave entirely like the original in every situation, which turns out not to be quite true. Others worry that the duplicate will cause all sorts of problems because it’s not enough like the original, resulting in extra, unnecessary steps. To untangle things, let’s start with the least ambiguous situation.
Swapping Your Startup Drive — Suppose your Mac’s internal hard drive dies completely, so you remove it from your Mac and replace it with the drive on which you’d previously stored your bootable duplicate. Your Mac doesn’t care about the fact that the new hard drive may have a different brand, capacity, or speed. All it knows is: here’s a disk with exactly the same data in exactly the same place. It is, for all practical purposes, the same disk. You can carry on as if nothing happened; everything, including your backups, should simply pick up where they left off, which is almost certainly what you want.
Now, there is one little catch. What if there was a time lag between when you made the duplicate and when you started using it? And what if, during that lag, you created or edited data on your startup disk — and backed it up to a destination other than where your bootable duplicate is stored? Now you have a startup disk that’s somewhat out of date, and to make it current, you’ll have to go to that other backup to locate and restore any important files that were changed after you last updated the duplicate. This, I’m sorry to say, is often an entirely manual procedure. In many backup apps (and again, I’m thinking especially of Time Machine and CrashPlan), there’s no simple way to say, “Show me all and only the
files that changed and were backed up after time x.” You may have to dig through folders one by one in your backup archive to find these files. You could ask the software to restore everything backed up after a certain time, overwriting any existing files, but that would take quite a while. It’s a pity that many otherwise highly competent backup apps don’t account for this usage case.
Booting from an External Drive — Although the situation I just described is the least ambiguous, it’s also relatively infrequent. The most likely scenario, which gets more confusing, is when your regular startup disk is still present and functional but you hook up your duplicate and boot from it temporarily. Perhaps you’re doing this to verify that the duplicate works (in which case you may be running from the duplicate for only a few minutes), or perhaps your startup disk is having problems and you want to run a disk repair utility while carrying on with your regular work.
Either way, let me start by saying what isn’t a problem in this scenario. For one thing, it doesn’t matter if your startup disk is external. Apart from speed differences, your Mac should behave identically whether the startup disk is connected via an internal SATA port, USB, FireWire, Thunderbolt, or whatever. So, don’t let that trouble you in the least.
For another thing, it doesn’t matter if data happens to sync with the cloud while you’re booted from the duplicate. For example, if you use iCloud, your calendars, contacts, bookmarks, and so on will sync in the background. You need not worry that the outdated data already on your duplicate will somehow overwrite what’s in the cloud; on the contrary, the cloud has the “master” copy (sometimes called the “truth”), so it will bring the data on your duplicate disk up to date. Similarly, if you use Dropbox or another cloud-based file storage service, it will bring your disk up to date with the latest truth from the cloud, and it’s unnecessary for you to fret over that in the slightest.
(You do need to fret if you use POP for email, or if you have any rules or filters that file incoming email from IMAP or Exchange servers into local mailboxes. That could get messy, with the duplicate being changed in ways that can’t easily be applied back to the original, so if in doubt, refrain from checking your email at all while booted from the duplicate.)
You need not even worry about aliases — usually. When you create an alias to an item that’s on your current boot drive (that includes items in the Finder’s sidebar and in your Login Items list), Mac OS X creates relative links. That means if you make a duplicate, boot from the duplicate, and open an alias, the item that opens is the one on the duplicate, not on the original disk. (And that’s probably what you want.) That’s not to say your Mac might not have a script, a symbolic link you created in Terminal, or some other pointer that references a file or folder by disk name, and if it does, you could accidentally open the wrong copy of a file or application, or save data to the wrong disk. (If you’re concerned and
want to be absolutely sure which item you’re opening, navigate manually from the top level of your disk when booted from a duplicate.)
However, at least one significant thing is most likely different, even though you may not notice it. If your duplicate had the same name as your startup disk (presumably the most common case), something slightly weird can occasionally happen. Mac OS X won’t let two mounted volumes have exactly the same name. In the Finder, they may look like they have the same name, but if you already have a volume called “Macintosh HD” mounted and then you mount a second one, behind the scenes, the second one gets a different working name (in this case, “Macintosh HD 1”). That’s because many things that happen on your Mac depend on being able to locate a disk by name, and if there were any ambiguity, a file might get put in the
wrong place.
Ordinarily, this on-the-fly renaming just works, but it’s not foolproof. What if, during the time you have both “Macintosh HD” and “Macintosh HD 1” mounted, another user on your network connects to your Mac and copies a file to what is now “Macintosh HD” — your duplicate? You might not notice it, and when you switch back to your usual startup disk, the file would be missing. Similar things can happen with file-synchronization apps, software downloads, and other operations. Furthermore, sometimes Mac OS X gets confused and doesn’t correctly update its behind-the-scenes list of volume names, so you could, for example, encounter a situation in which “Macintosh HD” is a volume you mounted after “Macintosh HD
1.”
On the other hand, renaming your duplicate doesn’t necessarily solve these problems. If your normal startup disk is named “Cindy” but you’ve booted temporarily from “Kate,” you may avoid mismatched name issues right now — but later, if you have to start using “Kate” permanently, apps and users that were still trying to save data to “Cindy” could get confused. All in all, I think you’ll get the best results if your duplicate has the same name as the original disk, but you should follow a few steps (just ahead) to avoid problems while running from the duplicate.
Meanwhile, you may have to think about another subtle background process: backups! After all, your backup software is probably configured to run automatically — perhaps once an hour (like Time Machine) or continuously (like CrashPlan). Backups usually don’t begin immediately when you boot your Mac, but they could easily kick in within 10 or 15 minutes. What if you’re planning to run your Mac from the duplicate for longer than that, but not permanently? Should you let your backups proceed — meaning they’ll be backing up the duplicate — or should you turn them off?
In general, there’s no harm, and considerable benefit, in letting backups run. Your backup software should act as though your duplicate is your regular startup disk and keep copying files to its normal destination as though you had restarted normally. That’s probably what you want, because if you create or modify a file while running from the duplicate, it can then be backed up. The problem is, in fact, with the opposite case: what if you modify a file but it isn’t backed up (perhaps because the time for the next periodic backup run hasn’t rolled around yet)? When you switch back to your regular startup disk, the file won’t be there (or won’t be current), and it won’t be in your backups either. It will still be on your
duplicate — but only if you think to check there before you update your duplicate the next time; doing so will probably delete the new file because it’s not on your startup disk.
Taking all this into account, here are my recommendations for what to do when you must boot from a duplicate for a short period of time:
- If you can avoid creating, modifying, or downloading files, do. If you can’t, make sure they’re synced to the cloud, copied back to your regular startup disk, backed up, or otherwise made available to yourself when you return to your usual disk later.
- Let regular, versioned backups (such as Time Machine and CrashPlan) run normally. But if (per the last point) you can’t avoid creating files, make sure your backup software has in fact backed them up before switching back to your customary disk.
-
Turn off any scheduled updates to your bootable duplicates. The last thing you want is for your duplicate disk to clone itself back onto your main startup disk while you’re testing it, or for the software to freak out in trying to clone the original over the now-booted duplicate.
-
Avoid letting other users connect to your Mac, especially to upload files.
Booting a Different Mac — There’s one more scenario to consider: booting one Mac with a duplicate of another Mac’s startup disk. For example, imagine that you created a duplicate of your iMac’s startup disk and then you had to take your iMac to the shop for repairs. In the meantime, you hook up your duplicate to your MacBook Pro so it can “pretend” to be the iMac. As long as the MacBook Pro supports the same version of Mac OS X your iMac was running, this arrangement should work fine — with, as you might have guessed, a couple of qualifications.
First, although this situation is ostensibly similar to the last one — booting a Mac temporarily from another drive — the time frame involved could be longer (days or weeks instead of hours). So, it’s impractical to avoid modifying files, checking your email, and the like. Therefore, I recommend that you use the duplicate disk on your MacBook Pro as you normally would use the internal drive on your iMac, and then — once your regular iMac is back in service — hook up the external duplicate and reverse the cloning process (copy everything from the external drive back to the iMac’s internal drive it started on).
Second, while your MacBook Pro is running from the duplicate, it will by almost every measure appear to be the iMac. It’ll even use the iMac’s name for file sharing, screen sharing, and the like. However, every Mac has several unique identifiers, including a serial number, a UUID (universally unique identifier), and a MAC (media access control) address for each network interface. Some pieces of software check one or more of these unique identifiers to verify that they’re still running on the same Mac on which they were authorized or licensed.
The most common example is iTunes. If you authorize your iMac to use your iTunes account and then start up your MacBook Pro with a duplicate of the iMac’s disk, that doesn’t mean the MacBook Pro is automatically authorized. You must authorize it manually, if you haven’t done so previously (in iTunes, choose Store > Authorize This Computer). But, if you’ve already run out of authorizations — Apple limits you to five — you may be out of luck unless you can deauthorize one of your other computers or reset all your authorizations, the latter being something that Apple allows you to do only once per year. Other software may make you jump through similar (or worse) hoops.
Don’t Sweat It — As convoluted as this all may sound, booting your Mac from a duplicate is usually a simple and problem-free operation. But it never hurts to have a better grip on what’s going on behind the scenes, just in case. In particular, think about whether you’re going to be using the duplicate long enough to add or modify files on it manually. If not, there’s no harm in simply switching back to the original. But if you are going to be working from the duplicate for any significant period of time, you’ll need to clone it back to the original when you’re done.
A final note: keep those duplicates up to date. It would be overkill to update them every hour, but once or twice a day is not a bad idea. Remember, the longer the gap between the last time you updated your duplicate and when you discovered you needed to boot from it, the greater the chance of missing or outdated files that you may have to laboriously restore.
Explore Alternatives to Google Reader
Google says it will shut down the Google Reader RSS aggregation and synchronization service on 1 July 2013. (For simplicity, we’ll use the familiar term “RSS” to mean both the RSS and Atom news feed formats, and the overall ecosystem of syndicated news feeds.) This comes despite the fact that Reader reportedly generates more traffic for publishers than the company’s Google+ service. It’s bad enough to lose the Web client, but because many RSS app developers relied on Google Reader to handle syncing and update retrieval, the future of many independent RSS readers is in doubt. This includes the venerable NetNewsWire for Mac OS X, currently owned by Black Pixel. (For more general pondering about what the Google Reader shutdown means, see Adam Engst’s “Thoughts Prompted by Google Reader’s Demise,” 14 March 2013.)
Developers, including Zite and Digg, are scrambling to fill the gap left by Google’s announcement. The RSS race is on, and we’re sure to see new developments by the time Google Reader goes dark. However, that does little to help Reader users now. Fortunately, several existing products can ease the pain of transition. Paul Bradshaw of the Online Journalism Blog posted a call for comments on Google Reader alternatives, and was
then nice enough to compile a spreadsheet of the results that lets you check out the field and compare competitors.
Get Takeout from Google — First things first. Export your subscription data from Google Reader so you have the flexibility of switching to another RSS reader at any time in the future. Google offers a direct method via its data portability site, Google Takeout. Visit the site, login if prompted, and click the Choose Services button. From the list of buttons that appears, click Reader and then click Create Archive. The file won’t be huge, but it will probably take a while for Google to build it. If you get tired of waiting, you can select the “Email me when ready” checkbox and do something else as it builds.

The Google Reader export is compiled as a downloadable Zip file. Inside are several JSON files with various metadata, but most important is the file called subscriptions.xml. This is an XML file in the OPML format, a standard import and export format for RSS readers. You can import this file into just about any RSS client to restore your Google Reader subscriptions.

(If you use NetNewsWire and sync with Google Reader, you can export your subscriptions locally. Make sure you have performed a sync and then chose File > Export Subscriptions to create an OPML file.)
Feed Me an Easy Solution — If you’re looking for a one-click transition, your best bet is Feedly, a Google Reader client that comes in a variety of forms, including a Web client, Chrome extension, Safari extension, Firefox add-on, iOS app, and Android app. Log into your Google Reader account from a Feedly client, and it presents your subscriptions in an attractive, magazine-like format that’s particularly nice on touch screens.
What’s most compelling about Feedly isn’t its looks, but its upcoming Normandy service for synchronizing your subscriptions between devices. When Google Reader shuts its doors, Normandy will take over on the back end, in what will hopefully be a seamless transition. Other developers can integrate support for Normandy, too.
Run a Fever — Nice as Feedly is, it requires that you rely on yet another company for your RSS-reading needs. If you can handle a bit of system administration, Fever is worth a look. Fever is a self-hosted news reader and feed aggregator. It costs $30, and you have to provide your own Unix server running Apache, MySQL, and PHP. If you have no idea what I just said, then Fever is not for you.
Fever and Google Reader are functionally equivalent. You read news in Fever through its Web client. Fever does set itself apart from Google Reader by sorting and compiling articles by “temperature,” a rating calculated by how many links and how much discussion the article has garnered.
Fever is particularly interesting for fans of the Reeder RSS client for the iPhone and iPod touch, since it already supports Fever in addition to Google Reader. Unfortunately, the Mac and iPad versions of Reeder don’t yet support Fever, so you have to turn to Fever’s Web app on those platforms. However, Fever does work via the site-specific browser Fluid on the Mac, which turns the Web interface into a Mac app, complete with a count of unread items in the Dock. For another dedicated Fever client for the iPhone and iPod touch, check out Sunstroke.
Good Vibe-rations — Google isn’t just killing Reader, it’s also shutting down iGoogle, its personalized Web portal, as of 1 November 2013. Fortunately, there’s a blast from the past that can replace both: Netvibes.
Netvibes started years ago as a personalized Web portal, like iGoogle, but has since evolved into a RSS reader as well. You can switch between modes with a click. In widget mode, each of your feed folders shows up as a tab, and each feed is its own widget. This mode is awkward for reading, so most will probably prefer the reader mode, where feeds are presented in a more-traditional style.
Netvibes’s extra juice comes from adding more than just RSS feeds to your interface. There are widgets for email, Google Analytics, weather, and more. There’s also a respectable mobile site, though for some reason if you save it to your iPhone’s home screen, the resulting Web app doesn’t fill the iPhone 5’s screen.
Unfortunately, Netvibes is showing its age. Its design is outdated, and it feels slow and clunky. However, if you’re hurting from losing both Google Reader and iGoogle, it’s a decent stopgap. And Netvibes lets you export your feeds, so it’s easy to move on to greener pastures later on.
RSS: I’m Not Dead Yet! — Google has given neither users nor developers much time to respond to the shuttering of Google Reader. While several alternatives already exist and more will arise, the transition will break many apps that rely on Google Reader’s synchronization capabilities when developers choose not to update their software or users fail to migrate in time.
But fear not, RSS lovers. Useful Internet technologies always evolve to meet the ever-changing environment. There’s no better proof of that than the persistence of email, which remains the primary form of communication for most professionals. Email is based on open standards, has no central authority, and can’t be controlled by a corporate behemoth, unlike social networking services Google+, Facebook, and Twitter. If the online outrage over the death of Google Reader is any indication, syndicating Web updates via RSS and Atom feeds will remain viable into the foreseeable future.
Rather than suffering from the Three Horsemen of the Techpocalypse — Fear, Uncertainty, and Doubt — RSS aficionados should rejoice. By providing a good solution for free, Google Reader has essentially monopolized aspects of the overall RSS world for many years, and its upcoming death has inspired countless developers to build alternatives that will undoubtedly look not just to replace Google Reader but also to go well beyond it.
Thoughts Prompted by Google Reader’s Demise
I’ll be the first to admit that I never particularly used an RSS reader. Sure, I have NetNewsWire on my Mac, with a couple dozen subscriptions, but I launch it only a few times a year, usually when some question about our internal RSS feeds comes up. I also have a Google Reader account, but log into it roughly as often. What little I do with RSS, I funnel into my email via the Blogtrottr RSS-to-email service. (I’m thus translating the serial medium of RSS into the serial medium of email — see Internet pioneer Brad Templeton’s take on the issue, where he makes some wonderfully astute distinctions between
serial, browsed, and sampled media.)
Thus, Google’s announcement that the company would be shuttering Google Reader as of 1 July 2013 doesn’t affect me much, but it’s impossible to ignore the plaintive cries from the many loyal Google Reader users. “Why are you abandoning us, Google?” they ask. “What are we supposed to do now?” For some practical answers to the latter question, see “Explore Alternatives to Google Reader” (17 March 2013), and as to the former, all we have to go on is Google’s public claim that “over the years usage has declined.”
But what’s behind this move, and what does it mean more generally? It means, for one, that while it’s increasingly impossible to avoid relying on cloud-based tools, anything out on the Internet can disappear without warning. It also points out some interesting distinctions between tools and platforms, and the increasing tension between publishers — a role occupied by anyone who produces content on the Internet, which is just about everyone — and the massively powerful distributors like Google, Facebook, and Twitter. And finally, Google Reader is yet another casualty in the silent war being waged against us by the infinite amount of information on the Internet.
Up in Smoke — It’s said that change is inevitable, and that we should get used to it. But I’d argue that’s not actually true — for most adults, life is more the same than different every day. Throughout their lives, most people have only one or two spouses, one or two children, a handful of houses, and a small number of jobs. At age 45, Tonya and I have owned only five cars in our adult lives, and only three in the 22 years since 1991, when we bought our first new one after several used models. Although we have more Macs than most people due to our business, we still go 3 to 5 years between new computers. Day in and day out, we live our lives much the way we did
last week and last month, and in the broad strokes, each year tends to recapitulate the previous years.
All this is by way of saying that we — and I’m talking generally here again — get used to things being the same, because they usually are the same, and that applies just as much to the tools we use and the ways we become accustomed to working. In the past, change came less frequently, but in today’s hyper-competitive world where massive companies are playing for unimaginably high stakes, an insane rate of change has become a competitive necessity. Apple and Google and Microsoft all need to keep rolling out updated versions of their mobile operating systems to seem fresh and hip for new and jaded smartphone customers, and Facebook and Twitter and Google are constantly revising their social networking engines and interfaces to
remain compelling to their audiences.
But a psychological toll is exacted on many people whenever something major changes. Sure, some people thrive on exciting new features and constantly having to adjust their ways of working, but for those people who rely on established habits and time-tested procedures to be productive, change can be frustrating, exhausting, overwhelming, and downright scary. At least Google is providing a few months warning before Google Reader’s switch will be thrown, and Apple gave users even more warning with the massive transition from MobileMe to iCloud. But iTunes 11, for instance, caused much pulling of hair and gnashing of teeth for many people who didn’t know in advance it was going to be so visually and experientially different from iTunes
10.7. They don’t care that iTunes 11 can do virtually everything that iTunes 10.7 can do; they care that they’ve been thrust into an unfamiliar world and must laboriously map out pathways and identify landmarks en route to that unchanged functionality (see “Redesigned iTunes 11 Brings iCloud Streaming and New MiniPlayer,” 30 November 2012).
The heart of the problem is integration via the cloud. With Google Reader, users are squawking not just because some will be forced to switch to another RSS reader, of which there are many, but because Google Reader provided a synchronization service that many RSS readers relied on. We’re not losing a single RSS reader; we’re losing what many developers had considered a building block upon which they could construct elegant software. Developers all build on the shoulders of others, but only with the rise of cloud integration have those shoulders become unsteady. iTunes 11 is relevant here too; even though iTunes 10.7 remains functional for now, it’s inevitable that integration with the iTunes Store or new iOS hardware will ring
10.7’s death knell.
I have no happy answers here. Though I may not be a major Google Reader user, I too rely heavily on a wide variety of cloud services, and if one of them were to disappear, I’d be at a loss. I’ve seen this happen enough that I wouldn’t take it as personally as I’ve seen many people (and, let’s be honest here, older people in particular) take other changes, whether we’re talking about iWeb or iDisk or Google Sync or Twitter’s elimination of developer capabilities. All I can suggest is that you think about your tools and systems and consider what would happen if one might disappear. As has been said about losing data, it’s a matter of when, not if.
Tools Versus Platforms — Introducing Twitter into the previous discussion offers a nice segue into another topic raised by Google Reader’s closing, that of tools versus platforms. Twitter became popular in large part because of its open API, which enabled developers to create all sorts of Twitter clients and Web services based on Twitter data. But the company has been limiting what is possible, largely because Twitter’s business model relies on selling ads, and it can guarantee display only if Twitter controls the user experience. In essence, Twitter moved from being a tool to being a platform, and in the process is causing App.net to rise up to fill that void (see
“New App.net Social Network Aspires Beyond Chat and Ads,” 28 August 2012).
Google has long been a purveyor of tools as well, and Google Reader was one of them, particularly in terms of its synchronization service. Many of Google’s tools came from its vaunted 20-percent projects, where engineers were allowed to spend 20 percent of their time on anything that interested them. The result was a flowering of tools and services, but nowadays, those flowers look more like weeds distracting Google from its core businesses. Most notably, Google has focused a vast amount of its effort on Google+, thanks to the realization that if it didn’t do something, Facebook’s social approach might one day become a more-compelling platform for ads than Google Search. But like Facebook and Twitter, Google+ is a platform, not a
tool, and while Google may open up aspects of Google+ via an API, it’s unlikely ever to be usable in the background without users noticing, as Google Reader was.
This trend of companies moving from tools to platforms isn’t surprising, and makes sense for both users and providers. Platforms provide coherent user experiences, making things easier and more understandable for increasingly non-technical users. And platforms are largely self-contained, ensuring that the company in charge doesn’t have to share control or worry about competition within the platform. Platforms are also harder to leave — if you become accustomed to the look and feel and content of Facebook, you’re less likely to jump ship for Google+. It’s exactly the same strategy Apple is employing with iOS to prevent users from switching to Android or Windows Mobile (and, of course, Google and Microsoft are using this
approach as well).
But the loss of tools is disturbing, for the same reasons it would be disturbing if there were no more tools available for carpenters to build houses, just pre-fab structures trucked in and plopped down. Tools enable creative people to build things that no one else can even imagine, and just as a hammer and saw can be used for far more than building a house, so too can digital tools be used in ways that were never intended initially. I don’t have time to use App.net as a microblogging service like Twitter, but I wholeheartedly support App.net’s role as an infrastructure service for others to build upon. It’s a shame that Google is increasingly getting out of the tools business, much as it may make sense for them, but we can hope
that other companies will fill the holes left behind.
Publishers Versus Distributors — Though Google said nothing about Google+ in relation to the shuttering of Google Reader, many pundits have suggested that Google Reader’s time has come and gone, because where we are (or should be, for holdouts) now getting our news is via Twitter, Facebook, and Google+. And certainly, social marketing mavens will tell any company that will listen that it is doomed — doomed, I say! — unless it starts tweeting or maintaining a Google+ page or garnering “likes” on Facebook.
But there’s a problem with social networks. OK, there are a vast number of problems with social networks, but the one I want to focus on ties in with the platform point I made above, which is that we’re all publishers, whereas social media platforms — Google+, Facebook, and Twitter — have become our distributors. They rely on us for content, of course, but we rely on them much more, and that should set off warning bells.
Sure, if all you post is what you had for lunch and cute cat pictures, you probably don’t care that you have no permanent control over your content. If you’re a company and need to get the word out about your products, though, you’d be nuts to rely exclusively on a platform you don’t control and that could disappear or start charging usurious fees tomorrow. If you have a company blog and associated RSS feed, you might lose readers due to the loss of Google Reader, but at least you still have complete control over your content and your readers can find it again easily. (Me being old school, I’d suggest that better yet is having your own mailing list server and maintaining contact via email, since then no one can trip you
up.)
Worse, social networks are streams. From what I’ve seen, most people don’t monitor social networks non-stop, especially if they follow a lot of sources that aren’t close personal friends. With the volume of posts being what it is, most people don’t go far back in time to catch up after being offline for a while. So any post you make, if it doesn’t happen to appear in a window of attention, is likely to go completely unnoticed. Contrast that with an RSS reader that, while it requires specific attention, is more than happy to hold on to headlines until they’ve been read or marked as such.
At War with the Infinite — Lastly, and I hope to explore this more in a future article as well, I think Google Reader is largely a victim of the war we’re fighting — and losing! — against the infinite amount of information on the Internet.
To recap, first there was email, and not long after, Usenet news. Email is the unstoppable cockroach of Internet technologies, but Usenet news grew so expansive that it engendered highly sophisticated software for dealing with subscriptions before losing its place in the limelight to the Web and slowly crumbling under its own size. In the early days of the Web, there were few enough Web sites that when we made our home pages, we all made lists of our favorite sites. When the number of Web sites grew too large, human-built directories like Yahoo sprung up to categorize all the sites on the Internet. Before long, those directories were kicked aside in favor of search engines, again because there were too many sites and too much content on
any given site to categorize. Then news hit, in a big way, via professional publications and blogs alike, and everyone who had previously made lists of Web sites started a blog. With so many blogs to check regularly, RSS became necessary as a way to make it possible to scan hundreds of headlines per day. Curated aggregation sites like Slashdot and Daring Fireball weren’t far behind, because even keeping up with an RSS reader was too much for many people. With the rise of Twitter and Tumblr and Facebook, it became too hard to justify the effort in maintaining a personal blog, when it was so much easier to post short messages and interesting links.
Google Reader, like other RSS readers, was an attempt to maintain control over the amount of information on the Internet, but like all such attempts, it was doomed to failure. The amount of information on the Internet is now, for all practical purposes, infinite. Actually, it’s even worse than that, since even just the information that interests us, or the daily news about the information that interests us, is essentially infinite, in the sense that we live finite lives and stand no chance of ever reading it all. (Yes, I realize there are people whose interests aren’t terribly broad, but it’s nearly impossible even to keep up with a sports team or two, or a few celebrities.)
Those pundits I mentioned earlier who claim that they’re getting all the news they need from social media instead of RSS readers are basically saying that they were overwhelmed by their chosen RSS feeds and consider Twitter or Facebook or Google+ more manageable. And indeed, if you follow people who share your interests, you’ll be rewarded with worthwhile posts and links. But there are some perhaps unanticipated issues with this approach.
What you’ll get is highly selective, but it’s selected by other people, not you. Perhaps that’s good, perhaps not. You will also miss posts — go offline overnight to sleep, and catching up the next morning is likely to be too much bother. Again, that may be good, in cutting down on the amount of information in your life, or it may be bad, if you miss something you would have deemed highly important. The good stuff may stick around in conversation anyway — I’ve long joked that I’m interested only in mainstream news that’s going to still be in the news two weeks later.
All that said, it’s easy to follow another person here and another company there, confirm a few new “friends,” or add someone to a circle, and before long, I’m willing to bet that social media services succumb to the soul-crushing power of the infinite as well, just like Usenet newsgroups and Yahoo’s Web site directory and now Google Reader. For many people, they already have.
To be fair, Joe Kissell had it right in “It’s Not Email That’s Broken, It’s You” (23 February 2013). Just as email isn’t broken, RSS readers aren’t broken, and social networking services aren’t broken. We’re broken, because we’re both finite and hardwired to be interested in a wide variety of things: other people, tribes, power, sex, social position, and — of course — kittens. Our only weapon in the war against the infinite is self-control. Subscribe to too many mailing lists, read too many newsgroups, track too many blogs via RSS, follow too many people on social networking services — regardless of the specifics, if you overindulge in information, no matter how
good your tools, you will eventually be crushed by the infinite.
TidBITS Watchlist: Notable Software Updates for 18 March 2013
Security Update 2013-001 for Snow Leopard and Lion — Apple has released Security Update 2013-001 for Mac OS X 10.6 Snow Leopard and 10.7 Lion, with each big cat getting two versions: Snow Leopard (316.63 MB) and Snow Leopard Server (391.63 MB); and Lion (31.42 MB) and Lion Server (79.33 MB). The updates close a variety of vulnerabilities, including Apache HTTP authentication, handling of JSON data by Ruby on Rails in Podcast Producer Server, and a buffer overflow when viewing
MP4 files in QuickTime. The complete list of fixes can be found on this Apple support page, which combines the details for these security updates with those for the just-released Mountain Lion update (see “OS X 10.8.3 Mountain Lion Fixes Nagging Bugs,” 14 March 2013). The security update also runs a malware removal tool that will notify you only if anything is removed. It’s interesting to see Apple releasing this update for 10.6 Snow Leopard, since Apple generally maintains security updates only one version behind the current cat. (Free)
Read/post comments about Security Update 2013-001 for Snow Leopard and Lion.
MacBook Pro Retina SMC Update 1.1 — Apple has issued MacBook Pro Retina SMC Update v1.1, which provides a fix for a “rare issue” for slow frame rates while playing graphics-intensive games on the 15-inch model of the MacBook Pro with Retina display. The System Management Controller update also provides bug fixes for Power Nap and wake from sleep, as well as a fix for a fan control issue. While the latter isn’t detailed in the release notes, it most likely addresses the overzealous fan spinning that’s been discussed at great length on Apple’s support
forums and noted at Geek.com. After installing, the SMC will be updated to version 2.3f35. (Free, 504 KB)
Read/post comments about MacBook Pro Retina SMC Update 1.1.
Pear Note 3.1 — Useful Fruit Software has released Pear Note 3.1 with full support for Retina displays on Macs. The multimedia note-taking app adds support for using images (like photos of slides in a lecture!) in the just-updated Pear Note for iOS 2.1, and it now saves documents in an updated format that can be read by the iOS app. For older Pear Note documents that include images, Useful Fruit suggests opening and re-saving them so they work properly with the iOS app. The release also fixes a bug with saving that caused slides to move back, an
issue where shared documents with special characters displayed improperly when hosted on Dropbox, and bugs associated with Spotlight results and the Quick Look generator. Finally, the Mac App Store version is now sandboxed. ($39.99 new, free update, 4.6 MB, release notes)
Read/post comments about Pear Note 3.1.
LaunchBar 5.4.2 — Objective Development has released LaunchBar 5.4.2 with improvements in indexing actions, services, and applications for the keyboard-based launcher. In addition to an overall performance boost to LaunchBar’s indexing engine, the update now recognizes executable shell scripts more reliably (even if they have filename extensions), ignores iOS apps when indexing applications, and improves 1Password indexing (especially on systems with multiple installed versions of 1Password). The release also replaces the previously used generic category icons in iTunes (Albums, Genres, Playlists, etc.) with
dedicated icons, and it fixes a problem with the Play from Album option that started playing from the beginning of the album rather than the selected track. Finally, LaunchBar 5.4.2 fixes a bug with determining the originator of a copy operation when triggered with a mouse click (instead of pressing Command-C), an issue with sending a labeled email address via Instant Send, and the appearance of double quotes in conjunction with Instant Send or Clipboard History. ($35 new with a 20-percent discount for TidBITS members, free update, 2.5 MB, release notes)
Read/post comments about LaunchBar 5.4.2.
Microsoft Office 2011 14.3.2 and 2008 12.3.6 — Microsoft has released Office 2011 14.3.2 and Office 2008 12.3.6, both of which address a security vulnerability that could “allow information disclosure if a user opens a specially crafted email message.” According to the security bulletin on Microsoft’s Web site, the updates ensure that both versions of Microsoft Office for Mac require user consent to download content from external sources.
Additionally, the Office 2011 14.3.2 update includes several fixes, primarily aimed at Outlook. It squashes a bug that didn’t save BCC recipients in Gmail IMAP draft messages, fixes an issue where messages were undeliverable if addressed to contacts that were created in x500 format, ensures that contractions aren’t marked as spelling errors, and fixes a problem with the Offline Address Book that wouldn’t update for some Office 365 users. The update also improves stability when using Track Changes and scrolling through a large Word document and fixes a problem with artifacts appearing during slideshow transitions in PowerPoint. (Free updates via the Office for Mac Web site or through Microsoft AutoUpdate, 113 MB/210 MB)
Read/post comments about Microsoft Office 2011 14.3.2 and 2008 12.3.6.
Default Folder X 4.5.8 — St. Clair Software has released Default Folder X 4.5.8 with a few more corrections to issues that cropped up in its two recent maintenance releases (see “Default Folder X 4.5.7,” 10 March 2013). Default Folder X can now be accessed in Java applications running in OS X 10.8 Mountain Lion. The update also fixes a bug that caused file dialogs to hang in Preview, TextEdit, and Mail after using Default Folder X’s menus, and it returns missing items to the utility menu and contextual menu. Other user interface-related corrections include
localizing the Quick Look command in the utility menu and contextual menus and adding VoiceOver labels to the Default Folder X toolbar buttons. ($34.95 new, $10 off for TidBITS members, free update, 11.4 MB, release notes)
Read/post comments about Default Folder X 4.5.8.
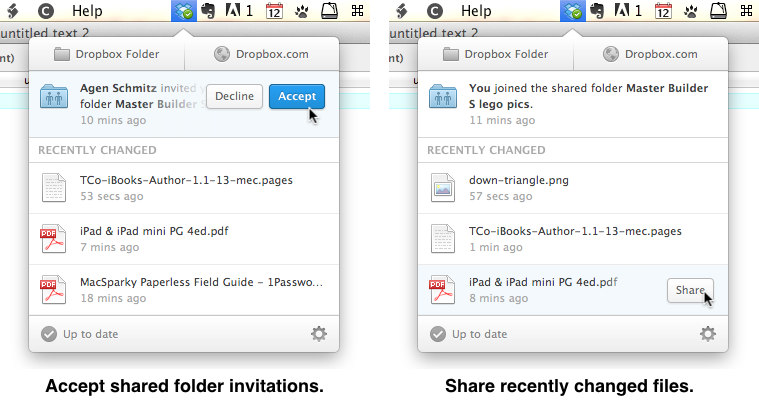
Dropbox 2.0 — While not a groundbreaking version jump in functionality, Dropbox 2.0 does significantly improve the interface available from its menu bar icon with an improved view of recently changed files as well as a new method for accepting shared folder invitations. Clicking the Dropbox icon in the menu bar now opens a window that displays buttons for opening the Dropbox folder and visiting the Dropbox Web site, plus a list of the three most recently changed files. When you mouse over one of the changed files, a Share button appears. However, clicking the Share button doesn’t engage an in-app sharing capability. Rather,
this action opens a Web browser to the file’s page on the Dropbox site, where you’ll need to click a Share button again to send a file’s link to an email recipient, share it on Facebook or Twitter, or copy the link to your Clipboard.
The redesigned window also includes notifications of new shared files and folders from other Dropbox users, which appear above the Recently Changed section. Mouse over an invitation to join a shared folder, and you can click the Accept button that appears to add it to your Dropbox folder (you can also click Decline). However, accepting a shared file (by clicking it in the window) again requires a visit to the Dropbox Web site, where you are given the option to download the file directly from the browser or add it to your Dropbox folder.
Other changes for the latest release include a fix for a bug that switched on discrete graphics for Mac laptops and added localization for Brazilian Portuguese. It’s available for Mac OS X 10.6 Snow Leopard and later. (Free update, 26.1 MB, release notes)
Read/post comments about Dropbox 2.0.
ExtraBITS for 18 March 2013
On the Web this week, Andy Rubin of Google’s Android team steps aside, Adam Engst talks about the demise of Google Reader and how tools are becoming platforms on MacVoices, Microsoft walks back a strict and unfriendly licensing scheme for Office for Mac 2011, and our brainboxes are puzzling the implications of Dropbox buying Mailbox.
Android Boss Brushed Aside in Spring Cleaning — Is it coincidence that Google CEO Larry Page announced that Android head Andy Rubin has “decided it’s time to hand over the reins and start a new chapter at Google” the same day Google released the latest projects that the company is dropping in “spring cleaning,” including Google Reader? It’s impossible to say what caused the replacement of Rubin with Sundar Pichai, who will add Android responsibilities to his Chrome and Apps leadership roles at Google, but it’s possible that Android was essentially getting too popular without actually
contributing that much to Google’s bottom line (only $550 million from 2008 through 2011, by some estimates). What changes Pichai will bring to the Android ecosystem — and how that will affect the iOS world — are a matter for speculation.
Adam Engst Riffs on the Google Reader News at MacVoices — In this discussion with host Chuck Joiner, Adam Engst delves into some of the more-subtle meanings of the news that Google Reader will disappear in a few months. In particular, Adam talks about the effects of tools morphing into platforms, the psychological effect that change has on users, and pricing models to support the concept that not all change is good for all users.
Microsoft Reverses Office Licensing Change — According to MacTech, Microsoft recently changed the original license agreement for Office for Mac 2011 to match Office 2013 for Windows, whose license prevented the transfer of the software from one computer to another. Microsoft reversed course on the Office 2013 licensing policies, once again allowing the software to be moved between computers (but no more than once every 90 days). Although Microsoft said nothing about the Mac version in its Windows Office announcement, MacTech learned that the reversal also applies to the Mac version.
In short, we’re back where we’d expect to be, but it’s distressing that Microsoft would even contemplate such an unfriendly license, much less implement it.
Dropbox Acquires Mailbox — Some acquisitions make sufficiently little sense when taken at face value that they signal a major future direction, are mostly about acquiring specific talent or technology, or are just utterly misconceived. Dropbox’s acquisition of the company behind the Mailbox iPhone app falls into one of those categories, but it’s unclear which just yet, given that making a quirky iOS email client seems far from Dropbox’s core mission. Despite protestations that the Mailbox app will continue, it seems entirely possible that it could share the fate
of the Sparrow email app, which, while still for sale, is no longer being developed after its developers joined Google in July 2012.