Help Build a Tool To Track Apple Support Page Changes
I have a project for someone out there! As I have admitted numerous times over the years, my development skills are weak at best, but I’ve come up with an idea for a tool that would benefit many Apple admins and consultants and, by extension, the rest of us.
Apple maintains an extensive knowledge base of thousands of pages of support articles that document many technical aspects of the company’s operating systems, apps, and devices. At TidBITS, we regularly link to these articles, and, thanks to a suggestion from reader Jolin Warren, my cleanup macro now trims the URLs so they should load in the default Apple Support site for your country.
Some time ago, I realized that Apple Support URLs follow numeric patterns. For instance, here are the URLs for Apple’s most recent security update release notes:
- iOS 16.7.9 and iPadOS 16.7.9: https://support.apple.com/en-us/HT214116
- iOS 17.6 and iPadOS 17.6: https://support.apple.com/en-us/HT214117
- macOS 12.7.6: https://support.apple.com/en-us/HT214118
- macOS 14.6: https://support.apple.com/en-us/HT214119
- macOS 13.6.8: https://support.apple.com/en-us/HT214120
- Safari 17.6: https://support.apple.com/en-us/HT214121
- tvOS 17.6: https://support.apple.com/en-us/HT214122
- visionOS 1.3: https://support.apple.com/en-us/HT214123
- watchOS 10.6: https://support.apple.com/en-us/HT214124
As you can see, the six-digit ID number after “HT” increments by one for each release, but the ID is assigned randomly to the releases. By creating more of these URLs by hand and guessing at some numbers, I determined that Apple has used other six-digit ranges over time. Many recent URLs start with 213 and 214, but I’ve also found URLs starting with 100–119 and 201–212. I haven’t discovered any pattern behind the ranges, and Apple skips some IDs for unknown reasons.
Leveraging This Realization
When I first figured out what Apple was doing, I considered using Dejal’s Web monitoring app Simon to tell me if any of these pages had changed. I didn’t get very far down that path because I couldn’t see any way to feed Simon thousands of URLs in a programmatic fashion, and it seemed like it might overload my Mac to check regularly. Other Web monitoring tools had the same problem—they’re designed to watch a handful of pages, not thousands.
Next, I created a Google Sheet that had a column for the six-digit ID, a column that appended each ID to the URL root, and a column that used the formula =Hyperlink($A2, IMPORTXML($A2,"//title")) to look up and bring in a hyperlinked title of the resulting page. Not all IDs map to active pages, so some cells were filled with #N/A.
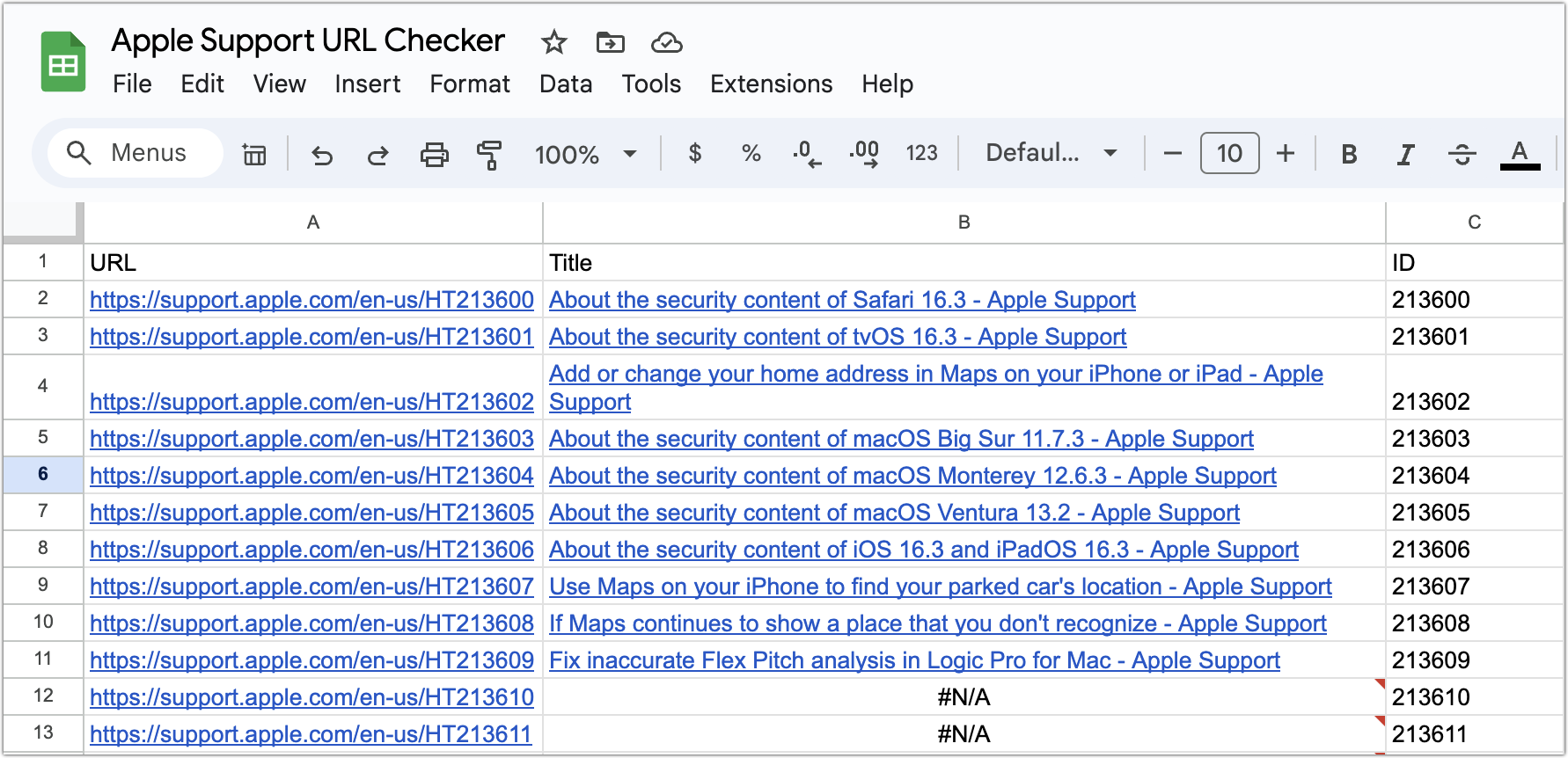
Success? The problem is that when I fill the rows down, Google Sheets gives up at some point because there are too many outgoing calls to Apple’s support site. Then all I see is “Loading…” even though clicking one of the URLs shows the traditional preview.
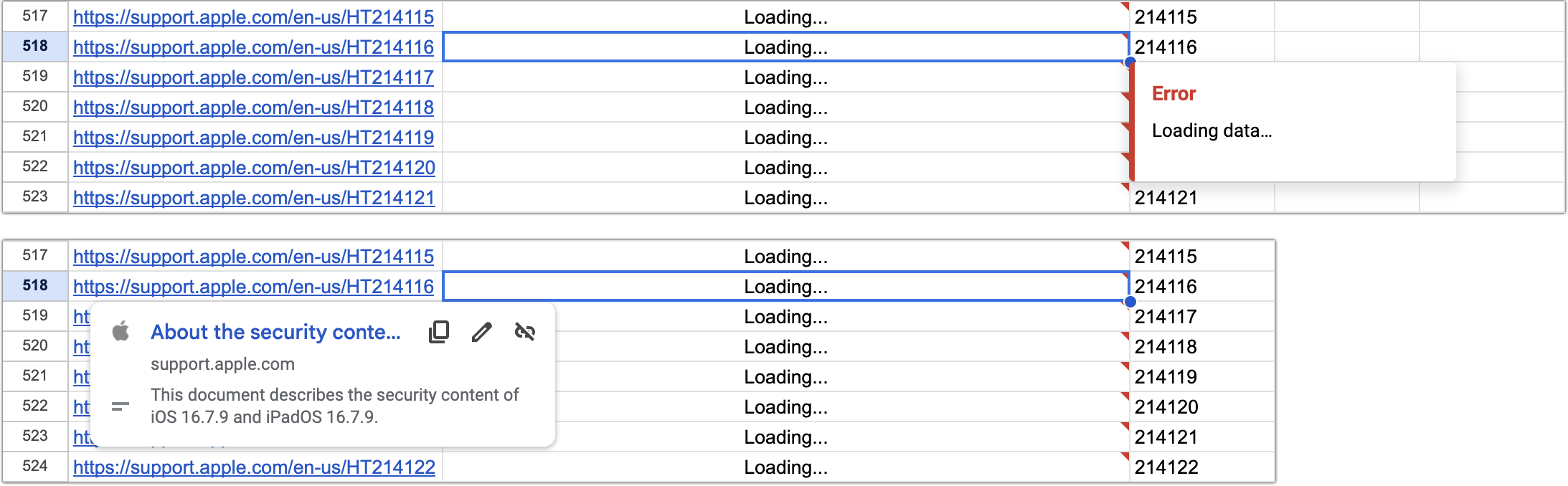
Shortly after this, I got a press release from a company called Neptyne, which was releasing an add-on for Google Sheets that would enable a programmer to interact with data in Google Sheets using Python. I don’t know Python, but when I explained my goal to the Neptyne founder, Douwe Osinga, he took a swing at what I wanted. Because it was in Python, he could loop in such a way as to avoid causing Google Sheets to freak out. Plus, Douwe was able to extract the date and version from Apple’s pages, which allowed me to sort by date so I could see which pages had changed most recently. (I never figured out Apple’s version numbering scheme.)
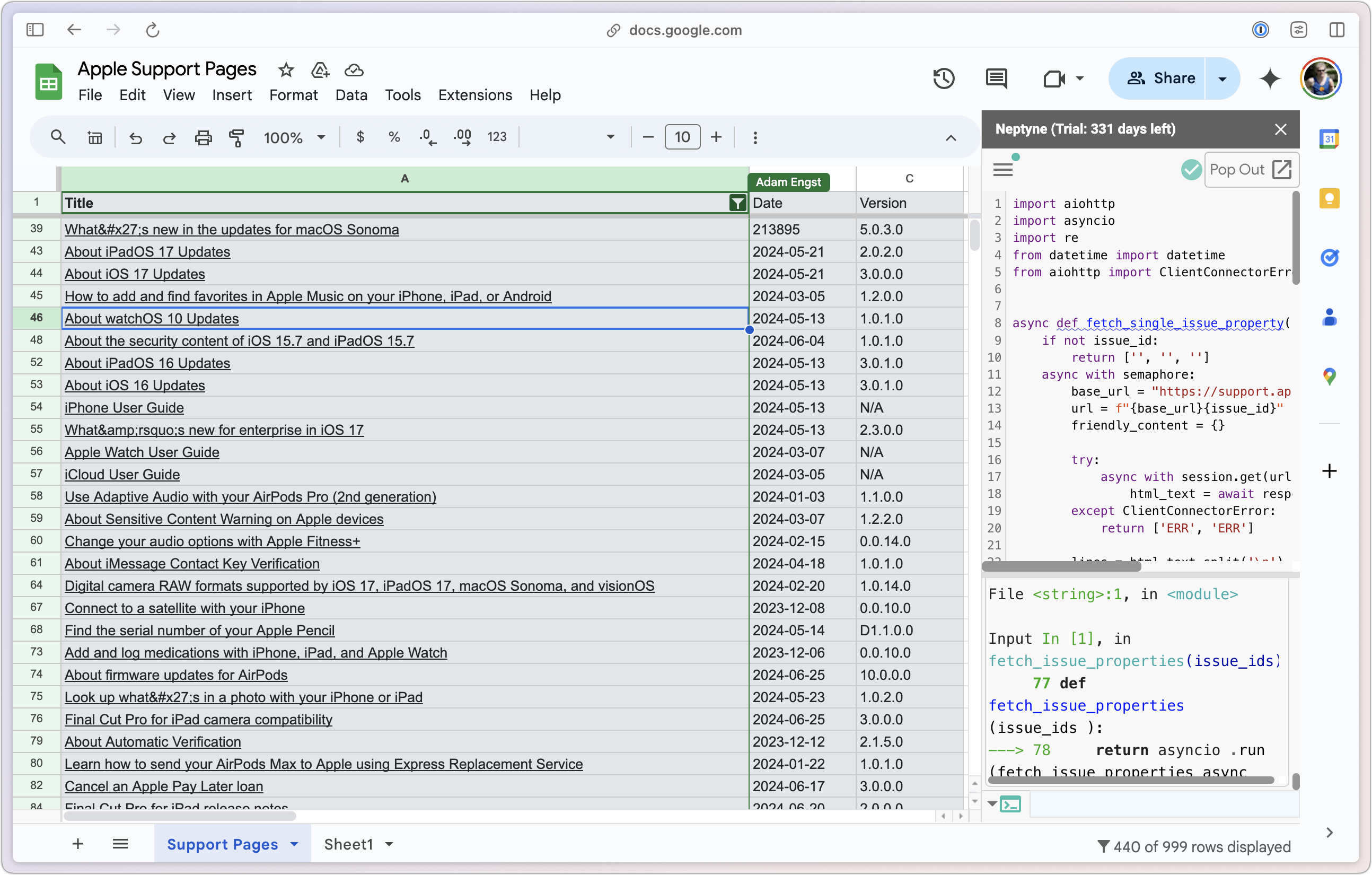
As much as this solution worked better initially, it was brittle. Adding more rows caused the whole thing to stop working, and I don’t know Python well enough to troubleshoot it, even with the aid of an AI chatbot.
But it suggested that what I wanted was possible. Imagine a world where you could learn about Apple’s technical changes as soon as they’re published, rather than having to stumble on them through a search later.
Apple Support Article Tracker
Being able to iterate through the universe of Apple support article URLs, retrieve the content, and sort the list by date was a good proof of concept. I don’t think Google Sheets is the right platform for this, and my research suggests that neither Excel nor Numbers are contenders either. Instead, I suspect we need a database with a Web-based front end for anyone to use. In my ideal world, the Web scraping would operate roughly like this:
- Traverse all possible Apple support URLs regularly, perhaps once per day or week. (Because it would act like a spider, it would need to honor robots.txt exclusions, throttle itself, and behave nicely.)
- On the first pass, load each page into a database, populating fields for title, date, version, and full text.
- On subsequent passes, save the content locally if it has changed from the previous save.
With the database storing the metadata, full text, and versions, the public website would need to:
- Display a list of all Apple support article titles, sorted by date, with access to previous versions.
- For any selected article and version, display a pane showing the rendered HTML.
- Provide a view that shows the differences between any two versions of an article.
- Offer alerts for new and changed articles, perhaps via RSS or email.
- Allow full-text searching. (Apple’s search engine is notably weak—see “Apple Launches Documentation Site for Manuals, Specs, and Downloads,” 25 March 2024.)
- For extra credit, provide a per-article discussion topic for annotations.
- For double extra credit, create an AI chatbot to allow conversations with the knowledge base, with answers referencing source pages.
I’d like to believe this wouldn’t be too difficult for someone with decent Web development chops, but it’s well outside my skill set. (Though he wasn’t volunteering to create it, Glenn Fleishman suggested that a Wiki site might be an easy way to store, diff, and present the data, plus provide options for community annotation.) I’m sharing the idea in the hope that someone finds it a compelling challenge and actually builds it. I’m happy to collaborate on the process and help with hosting if necessary. Are you game? Are there other features you’d like to see in such a tool?
Possible, certainly; worthwhile not so sure? That is a LOT of links to traverse, with multiple references to the same page, so you would need to keep track of pages you’ve already scanned… Wondering what would happen if a bunch of people started using it at the same time?
That’s why I suggest storing the pages in a local database for easy comparison. The system would scan Apple’s site on a regular schedule, perhaps once per day, following robots.txt rules, but all users accessing it would be dealing with the local database, not Apple’s site. Apart from general considerations when building an interactive website, I don’t see this as having any unusual usage concerns.
The idea of writing software to track every change across Apple’s support pages may seem beneficial on the surface, but it’s likely to be a massive waste of resources for several reasons:
Scale and Complexity: The sheer number of support pages Apple maintains means this tool would be continuously overburdened with trivial updates, like minor wording tweaks, drowning users in unnecessary notifications.
Redundancy with AI: AI advancements are already making such tasks obsolete. Within a few years, AI could handle this far more efficiently, rendering such a tool redundant.
Misguided Focus: Instead of tracking endless updates, focusing on significant content like key policy changes or new feature rollouts would be far more valuable. A tool dedicated to capturing every single change risks becoming a noise generator rather than a genuinely useful resource.
Investing time and energy into a project like this, given the direction of AI and the complexity involved, could be more trouble than it’s worth. A more strategic approach would involve leveraging AI to filter and highlight only the most critical updates.
Well, you’ve certainly got more experience with large scale websites than I. The few I’ve done were quite small, knock out in a text editor scale. Still seems a lot of work for small return to me.
Possibly, but none of your reasons are entirely convincing. #1 is possible but remains to be seen; #2 hasn’t happened yet; #3 is what TidBITS already does with its articles (also, this strikes me as similar to the old remark about MS Word – that no one uses more than 20% of its features, but it’s a different 20%. People are going to have wildly different ides about what’s important and what’s not).
As I said, I think this would be of interest mostly to Apple sysadmins and consultants, along with journalists like me, not a general-purpose site that everyday users would track. But I’d be able to use the results to inform articles that would surface information that otherwise remains nearly undiscoverable.
It is true that Apple makes small wording changes to its pages on occasion, as you can see if you compare versions in the Wayback Machine. But just as the Wayback Machine can distinguish between small and large changes, any system that can do a diff can do the same.
So it would be easy to give people the option to be notified of all changes or only large changes. A sufficiently flexible system could also let people pick and choose their topics—I could easily see someone caring only about changes affecting macOS and not visionOS, for instance.
As to your point about AI, today’s AI chatbots wouldn’t help here because they have limited insight into recently changed pages. Even AI-based search engines like Perplexity aren’t useful (I checked) because they retrieve only a small number of pages to answer queries, and they don’t have the ability to direct their searches with metadata such as modification date.
Have you looked at Airtable.com?
Perhaps checking the published date at the bottom of each file and only if that has been changed then process the new file.
The headers returned give you a lot of information, in particular
Cache-Control,ETag,Expires, andLast-Modified. For example:And by doing a
HEADrequest (which is whatcurl --headdoes in that example), you get just the headers. After looking at them if you decide you want the whole page, then you can do aGET.(
SS-Article-Versionlooks interesting too, but it’s a nonstandard header, so I don’t know exactly how Apple uses it.)I have, but it looked like a more-involved platform than I wanted to learn for a one-off project.
Interesting! I think that SS-Article-Version is what the Neptyne guy was able to access too. I could never figure Apple’s system surrounding those numbers.
From Apple’s terms of use:
That might present something of a barrier to what you propose.
Of course, if we take Apple’s terms of use at their word, we’re in violation by posting them here:
Interestingly, here’s what support.apple.com’s robots.txt says. It doesn’t seem perturbed about standard support articles.
Ron, you just violated the TOS by posting them here.
(DOUBLE EDIT: I mean, come on, that suggests that linking to Apple violates their TOS)
EDIT: Ninja’d!
I’ll be turning myself in to the Apple police, then. I’m so ashamed.

Yes, this seems very doable (I have 25+ years of experience in web applications, though it’s been a few years since I wrote code to crawl sites regularly). It might violate Apple’s terms for access to its pages, but by those rules, so does any browser that caches pages (spoiler: browsers almost invariably store and reproduce content from sites via caching) (however, I am not a lawyer). It’s not super hard to do something like this, but it does take some work to tread softly. Also, diffing HTML pages can be rather complicated (thought there are often viable “shortcuts” or workarounds).
One concern is that after building a tool to do this work, Apple might block the tool (via robots.txt or via legal means), which would render the effort a waste (I really don’t know if Apple would bother—I hardly think it’s worth their time, so I think the likelihood of problems is low).
With a smart intern and a good part-time advisor, I think this could be built in 1-2 months (not including showing visual diffs of versions of pages). I suspect that a small cloud virtual machine could fetch updates on at least a weekly basis (not sure about daily without knowing average latency as well as how many URLs need to be accessed; ETags and Last-Modified headers let you make conditional requests that can help a lot). Anyone have a “smart intern” available looking for this kind of work?
Yes, it absolutely would be useful. In the past, Apple Support had an RSS feed, but at some point it just stopped updating, and then eventually it got 404’ed. Indeed most changes were trivial, and multilingual, making following that feed quite tedious at times; nevertheless, it was really awesome.
Unfortunately I don’t think replicating this can ever be as good as that feed, and as noted you run the risk of hitting some anti-user/anti-scraping limit imposed by Apple’s web servers trying to make it work. Nevertheless I’d be interested in such a thing, if anyone ever figures out the schema the site uses, and how we could comprehensively scrape the support base.
Off-topic.
I am firmly convinced that more than 99% of organizations expect users not to read their terms of service. The immediate result is that I am firmly convinced that those organizations do not care if users adhere to terms of service. I am not a lawyer, this is not legal advice, and I think organizations should rein in their lawyers so that terms of service are easily readable.
Agreed, this is a job for RSS or even better Atom XML. Subscribe to feeds with alerts and firmware updates, etc.all the time. It would be immensely useful to pull any Apple Support Article updates.
But Apple needs to implement it and doing so properly takes some effort. Do it wrong and the feed is less useful. Plenty of broken or useless feeds out there.
Attempting to DIY with a scraping app and you risk Apple’s wrath. If such an app became popular it would be akin to a DDoS attack. If you do code something don’t share it. Don’t download every article, etc. not to mention copyright issues, etc.
Dunno about the technical side of things, but have to say that this would be an awesome idea, even for us norm users.
So go for it! ;-)
Sounds like a great project for a college coding group. Anyone have any connections with CS departments looking for projects? I can try to reach out to people at Cornell, but none of my friends are in quite the right area.
How about some code like this? You can put it in your crontab to run daily and email you if anything has changed in the last 7 days.
Looks interesting! I’ll give it a spin and see what it does. Seems like a great start.
I’ve been fiddling with this. It looks like a bunch dropped yesterday and today.
This is interesting, but what’s the idea? Parsing those specific URLs would only give you information about particular releases.
Note that if it’s just releases you’re after then Apple already have a page for all new releases, including the betas. You can follow it with RSS, too.
For security announcements, their mailing list is still working and they send PGP-signed email to it.
https://lists.apple.com/mailman/listinfo/security-announce/
My experience with security updates is that sometimes there are small updates that aren’t important in any way and other times Apple adds in CVE entries that it didn’t want to publicize for some reason initially. Diffing is the only way to know.
As with most programming things, everything is doable, usually comes down to a less frequently asked question of if it should be done. Seems like there’s a few different needs here.
The notification of changes seems a very common need and as others have stated, clearly best served by RSS or similar. Ideally this would come from Apple since it would be automatic when updating their pages. Might even be worth a feature request or bug report, perhaps on their support forums? Technically not a complicated feature, even without knowing their CMS.
To see what has actually changed, as @ace mentioned, requires a record of before/after and ability to diff. Legalities aside, the lazy developer in me cringes at the idea of duplicating all the pages and their versions. I agree it’s probably the only way you’d ever get that feature as Apple would never add it, but I just hate any unnecessary data duplication and syncing, it’s never as simple as it seems.
That being said, with some of the ideas posted earlier, it would be quite easy to use the URL IDs as uniqueIDs, store each version as a text blob, and then display the differences. It would probably be best to separate out the main content from all the html, simply to minimize the diffs to the most important information. One question never answered is if this is just an English language resource, or do we need to save the pages for every language?
Honestly the simplest way to get 95% of the features you’d want would be to use git since the problem you are talking about is versioning, with existing solutions. A public repository on GitHub would give you backups, diffing, versions, etc all built in. Using some of the ideas mentioned above, anytime a page is modified, simply download the raw URL, extract the main content div to the appropriate file, and do a git commit.
While the interface isn’t as “consumer level” friendly for diffing, it’s familiar to many, and as your suggesting this geared towards professionals, would be good enough. Honestly not sure how much easier you could make it other than making the diff feature more prominent than it is on GitHub; maybe making a shell site for the files that links directly to the diff view of any article.
All of that just brings me back to the irony that Apple is assuredly using some kind of versioning system for all those resources, so the entire thing would be duplication unfortunately.
As a side note Apple does have a similar feature on its developer site, and some of its support pages. It’s not a full diff, but it is exposing versions of the pages for when software updates change the interface. So the functionality exists.
One example, note the selectors at the top for the language (swift vs Objective-C) and API changes.
On the support side it took me a while to find an example of what I remembered, and I’m wondering if it’s only in the “guide” pages? But there are pages that have different OS versions in a drop down, that must be pulling different versions of content as it’s been updated.
Storing revisions so they can be compared is next on the to-do list.
I love hearing people kibbitz about this while others are fiddling with code in the background. :-)
Since we’re entertaining Adam, interestingly there seems to be a small faux pax in the published date tag on apple’s support pages. The raw HTML:
While not well defined, the convention seems to be that the dateTime property inside the time tag is usually in a machine readable format (ex “2024-04-26”). More significantly, no space before the beginning of the itemprop key makes parsing that questionable, and ideally the value for the dateTime would be encased in quotes, esp if using human readable format (ex: “April”).
Only checked a sample size of 2, but probably the same across all pages.
Definitely malformed HTML. Shame on Apple.
See also:
Apple has apparently just changed the URL scheme to a simple six-digit numbering approach, with all the old HT URLs redirecting. From MacAdmins News:
Another ASAT-fiddler here: my tool(s) are now able to retrieve, parse and store (in a local SQL-database) an(y??) number of different ranges of support notes, but before I am try my luck and take a look what comes when trying to download a range 100.000 to 999.999 …
Does anybody have any info which numbers now make sense to take a shot at?
Any suggestions? Or experiences what was successful?
Some very recent ones seem to be in the high 120000 range, so there is probably no need to go much higher than that in initial testing.
I’ve had very poor luck in guessing randomly at the low numbers in the new ranges.
As with some others here, I’m not a complete stranger to site-scraping scripts — though it’s been a little while since I’ve developed anything “big” enough to have to worry particularly about
robots.txtfiles.Still, I guess I have to wonder whether it’s really worth the time and effort. Wouldn’t a search-engine search on
site:support.apple.comsorted by recency give you what you’re looking for quickly?for the security content of recent releases, for example, or
for macOS 15.
The search-engine sites are already doing the heavy lifting, it seems to me…
Hmm, in the big-data projects I was on that would be the exact reason why you would want to do a tool like this … the search engine/retrieval approach works fine if you are OK with actively doing a search and interpreting the results when you want to review the status.
Adams suggestion works when you want to tool tell/alert you “heh, look here there is something new” and this is what you might want to look at/consider.
In my experience it boils down to what do you want to have a tool like this do for you.
No, because the goal is to learn what has changed, not search for something to see if it has changed.
Apple adds and changes information all the time, and I think lots of people would find that information helpful rather than having to stumble upon it later.